
自考《数据库原理》串讲—关系数据库的模式设计

第四章 关系数据库的模式设计
本章的理论性较强,学习时有无从下手的感觉,在学习时应多加思考,从概念出发去理解理论,前后的理论有较强的联系,因此要逐个理解,但对于理论的证明等内容则不必深究,本章重点是函数依赖,无损联接、保持依赖和范式的概念。
一、关系模式的设计问题( 识记 )
关系数据库 是以关系模型为基础的数据库,它利用关系来描述现实世界。一个关系既可以用来描述一个实体及其属性 ,也可以用来描述实体间的联系。关系实质上就是一张二维表 ,表的 行称为元组 ,列称为属性 .
关系模式是用来定义关系的,这里的关系模式我们可以简单地理解为一个表的结构,一个关系数据库包含一组关系,也就是包含一组二维表,这些二维表结构体的集合就构成数据库的模式(也可以理解为数据库的结构)。
关系数据库 设计理论包括三个方面内容: 数据依赖 、范式 、模式设计方法。核心内容是数据依赖。
泛关系模式 :把现实问题的所有属性组成一个关系模式R(U),这个关系模式就称为泛关系模式。
数据库模式 :把泛关系模式用一组关系模式的集合ρ来表示时,这个ρ就是数据库模式。
下面我们总结一下关系模式的相关内容从“大”到“小”的排列
泛关系模式→数据库模式→关系数据库→表结构→关系模式实例(表)→记录(行、列。)
关系模式的存储异常: 数据冗余 、更 新异常 、 插入异常和删除异常
二、函数依赖(FD)
1、函数依赖的定义 ( 领会 ):设有关系模式R(A1,A2,……An)或简记为R(U),X,Y是U的子集,r是R的任一具体关系,如果对r的任意两个元组t1,t2,由t1[X]=t2[X]导致t1[Y]=t2[Y],则称X函数决定Y,或Y函数依赖于X,记为X→Y.X→Y为模式R的一个函数依赖。
这个定义可以这样理解 :有一张设计好的二维表,X,Y是表的某些列(可以是一列,也可以是多列),若在表中的第t1行,和第t2行上的X值相等,那么必有t1行和t2行上的Y值也相等,这就是说Y函数依赖于X.
2、函数依赖的逻辑蕴涵 ( 识记 )
设F是关系模式R的一个函数依赖集,X,Y是R的属性子集,如果从F中的函数依赖能够推出X→Y,则称F逻辑蕴涵X→Y,记为F|=X→Y.
而函数依赖的闭包F + 是指被F逻辑蕴涵的函数依赖的全体构成的集合。
3、键和FD的关系 ( 领会 )
键是唯一标识实体的属性集。对于键和函数依赖的关系:有两个条件:设关系模式R(A1,A2……An),F是R上的函数依赖集,X是R的一个子集,
(1)X→A1A2……An∈F + (它的意思是X能够决定唯一的一个元组)
(2)不存在X的真子集Y,使得Y也能决定唯一的一个元组,则X就是R的一个候选键。(它的意思是X能决定唯一的一个元组但又没有多余的属性集)
包含在任何一个候选键中的属性称为主属性 ,不包含在任何键中的属性为非主属性(非键属性),注意主属性应当包含在候选键中。
4、函数依赖(FD)的推理规则 ( 简单应用 )
前面我们举的例子中是以实际经验来确定一个函数依赖的逻辑蕴涵,但是我们需要一个推理规则才能完全确定F或F+的所有函数依赖。
设有关系模式R(U),X,Y,Z,W均是U的子集,F是R上只涉及到U中属性的函数依赖集,推理规则如下:
自反律 :如果Y X U,则X→Y在R上成立。
增广律 :如果X→Y为F所蕴涵,Z U,则XZ→YZ在R上成立。(XZ表示X∪Z,下同)
传递律 :如果X→Y和Y→Z在R上成立,则X→Z在R上成立。
合并律 :如果X→Y和X→Z成立,那么X→YZ成立。
伪传递律 :如果X→Y和WY→Z成立,那么WX→Z成立。
分解律 :如果X→Y和Z Y成立,那么X→Z成立。
5、函数依赖推理规则的完备性 ( 识记 )
函数依赖推理规则系统(自反律、增广律和传递律)是完备的。由推理规则的完备性可得到两个重要结论:
属性集X + 中的每个属性A,都有X→A被F逻辑蕴涵,即X + 是所有由F逻辑蕴含X→A的属性A的集合。
F + 是所有利用Amstrong推理规则从F导出的函数依赖的集合
6、函数依赖集的等价和覆盖 ( 识记)
在关系模式R(U)上的两个函数依赖集F和G,如果 满足F + =G + ,则称F和G是 等价 的,称F和G等价也称F 覆盖 G或G覆盖F.
每个函数依赖集F都可以被一个 右部只有单属性的函数依赖集 G所覆盖。
如果函数依赖集合F满足:
(1)F中每一个函数依赖的右部都是单属性;
(2)F中的任一函数依赖X→A,其F-{X→A}是不等价的;
(3)F中的任一函数依赖X→A,Z为X的子集。(F-{X→A})∪{Z→A}与F不等价。
则称F为更小函数依赖集合。
如果函数依赖集F和G等价,并且G是更小集,那么称G是F的一个 更小覆盖 .
这一段并不要求掌握更小集的求法,但是应当通过其求法理解更小集的概念 .
三、关系模式的分解特性
1、 模式分解中存在的问题 :( 识记 )
模式分解 就是将一个泛关系模式 R分解成 数据库模式ρ ,以ρ代替R的过程。它不仅仅是属性集合的分解,它是对关系模式上的函数依赖集、以及关系模式的当前值分解的具体表现。
分解一个模式有很多方法,但是有的分解会出现失去函数依赖、或出现插入、删除异常等情况,而有的分解则不出现相关问题。
衡量一个分解的标准有三种: 分解具有无损联接 ; 分解要保持函数依赖 ;分解 既要保持依赖,又要具有无损联接 .
那么什么是无损联接呢?什么又是保持依赖?
2、 无损联接的定义和性质 ( 识记 )
设R是一关系模式,分解成ρ={R1,R2,……,Rk},F是R上的一个函数依赖集。无损联接就是指R中每一个满足F的关系r(也就是一个关系实例)都有r=π R1 (r)|X|π R2 (r)……|X|π R3 (r),即r为它在Ri上的投影的自然联接。
更简单的理解, 也就是说,分解后的关系 自然连接后 完全等于 分解前的 关系,则这个分解相对于F是无损联接分解。
设R的分解为ρ={R1,R2},F为R所满足的函数依赖集,则分解ρ具有无损联接性的 充分必要条件 是:
R1∩R2→(R1-R2)
R1∩R2→(R2-R1)
也就是说,分解后的两个模式的交能决定这两个模式的差集,即R1、R2的公共属性能够函数决定R1或R2中的其他属性 ,这样的分解就必定是无损联接分解 .
3、 保持函数依赖的分解 ( 识记 )
在分解过程中,要求模式分解的无损联接是必要的,只有无损联接分解才能保证任何一个关系能由它的那些投影进行自然联接得到恢复。
同时,分解关系模式时还应保证关系模式的函数依赖集在分解后仍在数据库模式中保持不变,这就是保持函数依赖的问题。也就是所有分解出的模式所满足的函数依赖的全体应当等价于原模式的函数依赖集。只有这样才能确保整个数据库中数据的语义完整性不受破坏。
四、关系模式的范式( 领会 )
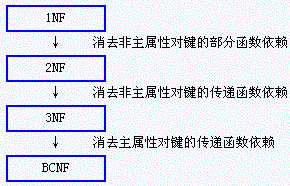
1、1NF、2NF、3NF、BCNF的定义:
1NF:第一范式 .
即关系模式中的属性的 值域 中 每一个值 都是 不可再分解 的值。如果某个数据库模式都是第一范式的,则称该数据库模式是属于第一范式的数据库模式。
2NF:第二范式 .
如果关系模式R为 第一范式 ,并且R中每一个 非主属性 完全函数依赖于 R的某个候选键,则称为 第二范式模式 .
在这里要先了解“非主属性”、“完全函数依赖”、“候选键”这三个名词的含义。
候选键 就是指可以唯一决定关系模式R中某元组值且不含有多余属性的属性集。
非主属性 也就是非键属性,指关系模式R中不包含在任何建中的属性。
设有函数依赖W→A,若存在X W,有X→A成立,那么称W→A是局部依赖,否则就称W→A是 完全函数依赖 .
在分析是否为第2范式时,应 首先确定 候选键 ,然后把关系模式中的非主属性与键的依赖关系进行考察,是否都为完全函数依赖,如是,则此关系模式为2NF.如果数据库模式中每个关系模式都是2NF的,则此数据库模式属于2NF的数据库模式。
3NF:第三范式 .
如果关系模式R是 第二范式 ,且 每 个 非主属性 都 不 传递依赖 于R的 候选键 ,则称R为第三范式的模式。
这里首先要了解 传递依赖 的含义: 在关系模式中,如果Y→X,X→A,且X不决定Y和A不属于X,那么Y→A是传递依赖。
注意的是,这里要求非主属性都不传递依赖于候选键。
BCNF :这个范式和第三范式有联系,它是3NF的改进形式。若关系模式R是 第一范式 ,且 每个属性 都 不 传递依赖于R的候选键。这种关系模式就是BCNF模式。
纵观四种范式,可以发现它们之间存在如下关系:
5、 分解成BCNF模式集的算法( 识记 )
对于任一关系模式,可找到一个分解达到3NF,且具有无损联接和保持函数依赖性。而对于BCNF分解,则可以保证无损联接但不一定能保证保持函数依赖集。
无损联接分解成BCNF模式集的算法:
(1)置初值ρ={R};
(2)如果ρ中所有关系模式都是BCNF,则转(4);
(3)如果ρ中有一个关系模式S不是BCNF,则S中必能找到一个函数依赖集X→A有X不是S的键,且A不属于X,设S 1 =XA,S 2 =S-A,用分解S 1 ,S 2 代替S,转(2);
(4)分解结束。输出ρ。
在这个过程中, 重点在于(3)步 ,判断哪个关系不是BCNF,并找到X和A.这里,S的判断用BCNF的定义,而X不是S的键则依靠分析。
6、 分解成3NF模式集( 识记 )
算法:
(1)如果R中的某些属性在F的所有依赖的左边和右边都不出现,那么这些属性可以从R中分出去,单独构成一个关系模式。
(2)如果F中有一个依赖X→A有XA→R,则ρ={R},转(4)
(3)对于F中每一个X→A,构成一个关系模式XA,如果F有有X→A 1 ,X→A 2 ……X→A n ,则可以用模式XA 1 A 2 ……A n 代替n个模式XA 1 ,XA 2 ……XA n ;
(4)w分解结束,输入ρ。
这个过程的 重点是这一句 “对于F中每一个X→A,构成一个关系模式XA”,这使我们的分解十分容易,然后依据合并律(合并律:如果X→Y和X→Z成立,那么X→YZ成立)将有关模式合并即得到所需3NF模式。
7、 模式设计方法的原则( 识记 )
关系模式R相对于函数依赖集F分解成数据库模式ρ={R 1 ,R 2 ……R k },一般具有下面 四项特性 :
ρ中每个关系模式R i 上应具有某种 范式性质 (3NF或BCNF)
无损联接 性。
保持函数依赖 集。
更小性 ,即ρ中模式个数应更少且模式中属性总数应更少。
一个好的模式设计方法应符合下列三条原则:
表达性
分离性
更小冗余性
8、多值依赖。简单了解一下。












关注添加

扫码加入备考交流群
与更多考生一起交流学习经验
备战考试,获取试题及资料

扫码下载APP
海量历年试题、备考资料
免费下载领取

扫码进入微信小程序
每日练题巩固、考前模拟实战
免费体验自考365海量试题







